

Building an amateur football scouting database is one of those things that looks straightforward from a distance but reveals its complexity the moment you sit down with a blank spreadsheet and a notebook full of half-formed observations from last Sunday’s match.
The scouting industry, for all its romance, runs on one thing above everything else: organised, searchable, consistently recorded information.
Without that, every player you watch is just a memory fading at the rate of the next game you attend.
The good news is that you no longer need a six-figure technology budget or a Premier League badge on your letterhead to build something genuinely useful. What you need is an understanding of the layers involved, a clear sense of what you are trying to capture, and the discipline to maintain the system once you have built it.
These three things, more than any single platform or tool, determine whether a scouting database becomes an asset or another folder on your desktop you eventually stop opening.
Understanding What a Scouting Database Is
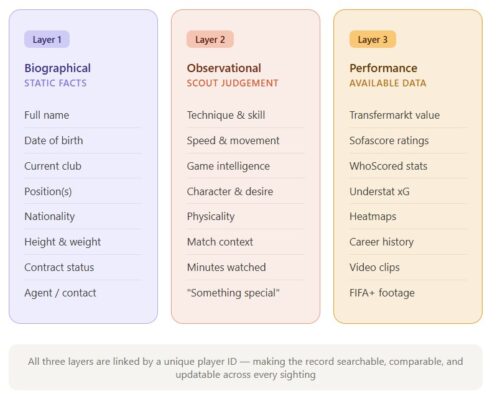
A scouting database is not a list of players. That contrast sounds small, but it shapes everything else about how you build one. A list of players is static, a snapshot of a moment.
A scouting database is a living record of observations, assessments, physical and biographical data, positional notes, contextual details about the match environment, and crucially, the evolution of a player across multiple viewings over time.
The professional scouting world has known this for decades, which is why clubs like Al Ahly rely on purpose-built platforms such as ScoutDecision, whose scouting team has described the platform as something that “greatly facilitates scouting reports, technical player assessments, and helps build a player database.”
The underlying logic is the same whether you are scouting for a club in Cairo or coordinating grassroots identification from a touchline in Indianna or Bristol. The database has to combine biographical facts, observational judgement, and performance data into something that can be searched, compared, and acted upon.
At the amateur level, this becomes even more important because the talent you are evaluating often exists in a vacuum of data.
There is no footage on Wyscout. There are no Opta metrics for a striker playing in the Pasadena Amateur League or a midfielder grinding through Sunday football in the East Midlands.
The database you build is, for many of these players, the only structured record of their abilities that exists anywhere. The responsibility that comes with that is worth sitting with before you open a spreadsheet.
CHECK OUT | How to Counter a High Press: A Tactical Guide
The Foundation: Deciding What You Need to Record
Before you touch a single tool, the most valuable work happens on paper. You need to decide what you are actually evaluating, because a database without a consistent evaluation framework produces data you cannot compare across players, and data you cannot compare is barely better than anecdotal notes in a WhatsApp thread.
The six-factor evaluation framework developed by Scout52, a platform built specifically for grassroots and youth football, offers a useful starting point for thinking about this.
Their structure covers Technique and Skill, Speed and Movement, Intelligence and Game Awareness, Character and Desire, Physicality, and what they describe as “Something Special,” which is that quality that resists quantification but tends to be the thing a scout remembers walking home from a game.
You do not have to adopt that exact structure, but you do need a structure with roughly that level of specificity, because vague categories produce vague entries and vague entries are useless when you are trying to compare a central midfielder you watched three weeks ago with one you saw yesterday.
The biographical data layer is simpler but no less important.
Every player entry should capture full name, date of birth, current club, position, nationality, height, weight, contract status if knowable, and a direct contact or agent detail where available.
These fields sound obvious, but the habit of filling them all in consistently, every time, for every player, is what separates a useful database from a disorganised pile of half-completed profiles.
Platforms like The Scouting App automate parts of this with an auto-fill system that instantly completes club, league, and performance information for players registered across their 600-plus competitions, but for amateur players in leagues those platforms do not cover, you are filling this in manually, which makes the habit even more critical.
Choosing Your Tools at the Right Stage
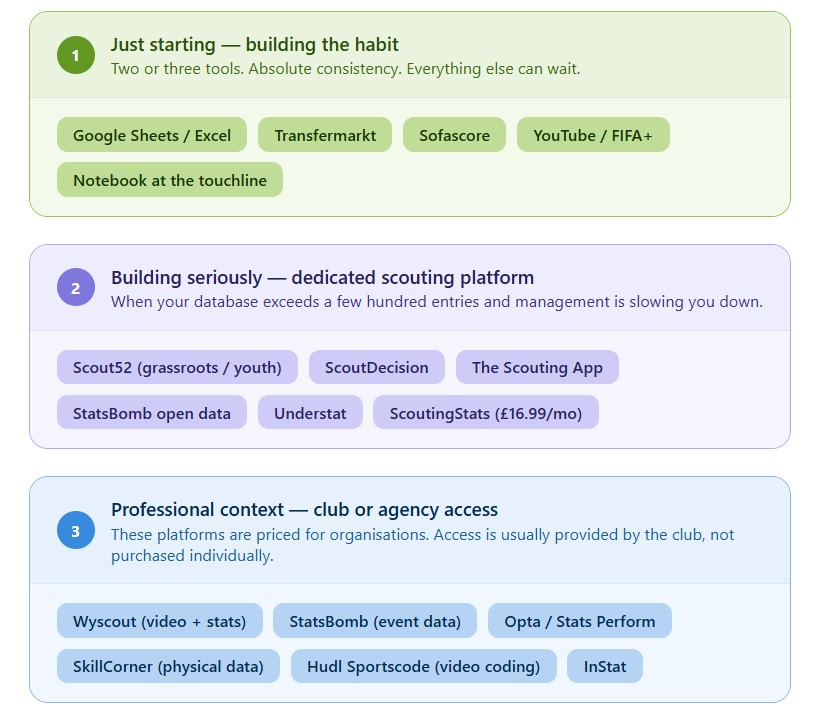
The single most counterproductive thing aspiring scouts do is try to build too elaborate a system too early. This is true of analysts, and it is equally true of scouts building their first databases.
Liam Henshaw, a data analyst and first-team scout at a global football agency, put it plainly in his 2026 toolkit guide:
“You need two or three tools that match where you are right now, and the discipline to get genuinely good at them.”
He was writing about analytics broadly, but the principle applies to database construction with equal force.
At the earliest stage, a well-structured Google Sheet or Excel workbook is a completely legitimate foundation. It costs nothing, works across all devices, requires no onboarding, and forces you to make structural decisions about your data that will serve you well when you eventually move to more sophisticated tools.
Henshaw noted that he still uses Excel daily for squad profiles, contract databases, longlist filtering, and data cleaning, not that it is the best tool for every job, but because its simplicity makes it reliable and fast for tasks that do not need complexity.
The structure of that spreadsheet matters hugely.
One sheet per player is a common amateur mistake that creates navigation nightmares within weeks. The more functional approach is a master player table with one row per sighting, not one row per player, so that you can track how a player develops across multiple observations without overwriting earlier assessments.
You then build a separate player profile table with the biographical and current-status data, linked by a unique player ID that you assign the first time you enter someone into the system. This relational structure, even within a flat tool like Google Sheets, keeps your data clean, searchable, and scalable.
CHECK OUT | Why Do Soccer Players Slide on Their Knees? Full Explanation
The Data Sources You Can Use
The football analytics data landscape shifted significantly earlier this year, and any guide to building a scouting database that does not account for what happened in January 2026 is working from an outdated map.
On 20 January 2026, Stats Perform terminated its data licence agreement with FBref, demanding the immediate removal of all advanced statistics from the site.
FBref had been the most accessible free source of Opta-powered advanced metrics for years, and the removal was described at the time as a “sad day for data democratisation” by Sports Reference president Sean Forman.
The timing, just eight days after Stats Perform was announced as FIFA’s exclusive betting data and streaming rights distributor for the 2026 World Cup, led many in the analytics community to interpret the move as commercially motivated, though Stats Perform denied any direct connection.
For amateur scouts building their own databases, the practical impact is this: FBref still has historical data going back years, and that archive remains genuinely useful for research and context on players who have moved through professional systems, but it no longer updates with the advanced metrics that made it so powerful for current-season analysis.
Any guide that still lists FBref as the primary free resource for live advanced statistics is simply out of date.
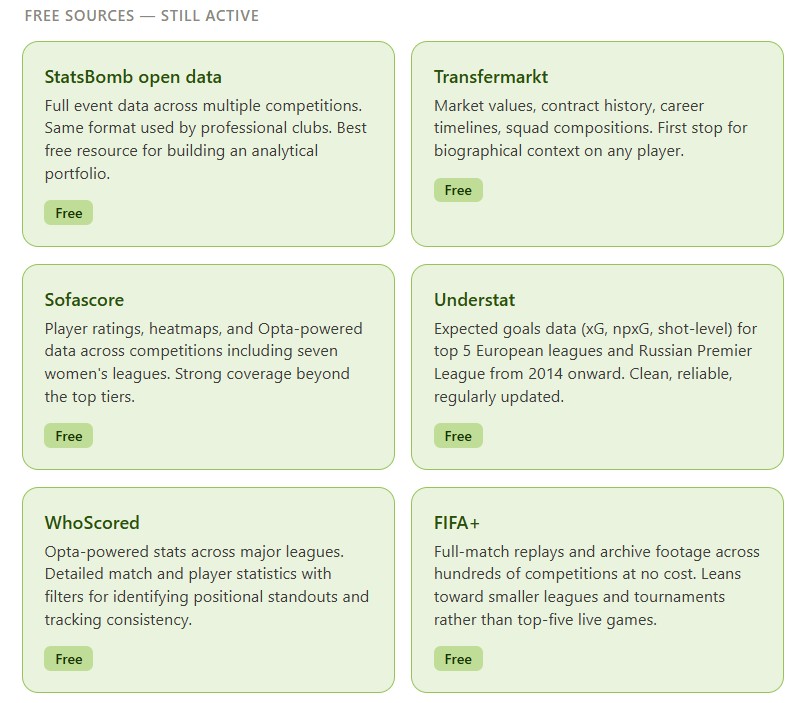
What fills that space now is a combination of sources rather than a single replacement. The StatsBomb open data library remains the strongest free resource for event-level data, offering full match events across multiple competitions with the same format used by professional clubs, which makes it particularly valuable if you are building analytical skills alongside your database.
Understat covers expected goals data across the top five European leagues and the Russian Premier League going back to 2014, with clean, reliable shot-level numbers. Sofascore, which carries Opta-powered data for seven women’s competitions among others, provides player ratings, heatmaps, and performance metrics across a wide range of competitions that extend well beyond the top tiers.
Transfermarkt remains indispensable for biographical context, market values, contract expiry data, and transfer history, and it remains entirely free. WhoScored, powered by Opta data, offers detailed match and player statistics across major leagues, with filtering tools that let you explore performance patterns and identify statistical standouts across positions.
For players in the amateur leagues you are actually covering, none of these will give you specific metrics.
That is the fundamental gap in grassroots scouting: professional data tools have no coverage of Sunday league football, regional competitions, or lower semi-professional tiers. This is precisely why your observations, your consistent, structured, methodical notes taken at the touchline, become the data.
The database you build is the only analytical record of those players that exists, and that makes it uniquely valuable rather than a poor substitute for something more sophisticated.
CHECK OUT | Soccer Scholarships in the USA: How to Apply and Get Accepted
When to Graduate From Spreadsheets
At a certain point, usually when your database contains several hundred entries and you are spending more time managing the structure than entering observations, a dedicated scouting platform makes sense. The field has expanded considerably, and the right choice depends almost entirely on what you are trying to do and what you can afford.
Scout52, built specifically for grassroots and youth football by experienced academy recruitment professionals, addresses the challenges that enterprise platforms like Wyscout simply ignore.
Its mobile-first design allows you to create structured reports during matches directly on your phone, which solves one of the most practical problems in grassroots scouting: the moment between watching something and writing it down. Its geographic coverage analytics produce heat maps showing which clubs, leagues, and areas you have scouted, with visual gap identification that helps you coordinate coverage systematically rather than instinctively.
From £18.99 per month, it sits well within reach of individual scouts.
ScoutDecision, which is used by clubs ranging from Southport FC in the English non-league pyramid to Al Ahly in Egypt, positions itself as a full workflow platform where biographical data, profile links, video clips, contracts, and scouting reports all live together rather than scattered across email threads, WhatsApp messages, Google Drive folders, and Excel files.
It allows you to import data from Wyscout and StatsBomb where that data exists, and build out custom evaluation frameworks for players in leagues those platforms do not cover. The platform generates automatic comparisons, which is genuinely useful when you are trying to contextualise one player’s profile against another across a large database.
The Scouting App takes a similar approach with its 600-plus competition database and 440 evaluation parameters, emphasising the combination of objective data and subjective scouting judgement in a single interface.
ScoutingStats, meanwhile, positions itself between the consumer-facing tools and the enterprise tier, offering a 40,000-plus player database, 50-plus metrics per player, a similar-player finder that can return the 30 closest matches to any target player across 50-plus leagues, and a report builder that generates shareable PDFs from live data, all from £16.99 per month.
For professional-level data with professional-level budgets, Wyscout remains the industry standard, covering 200-plus competitions with integrated video and detailed statistics, though its pricing now requires organisation-level engagement following the discontinuation of individual tiers.
The critical lesson from all of this is what Scout52 states plainly in its own documentation: “Simple, consistent data entry beats elaborate systems that are not maintained.” The most sophisticated platform in the world is worthless if you stop entering data into it three months after you subscribe.
How to Structure Your Evaluation Reports

The report attached to each player entry is where the database does its deepest work. A scouting report is not a stat dump and it is not a paragraph of impressions. It is a structured recommendation, combining what you observed, the context that shaped what you observed, and a clear judgement about where this player sits relative to what you are looking for.
The Professional Football Scouts Association provides standardised opposition and individual analysis report templates used across the network from the National League to European competition, and the structure they use reflects what matters at every level: physical profile first, positional role and defensive/offensive behaviour second, individual technical attributes third, a contextual note about the match environment, and a recommendation tier at the close.
ScoutDecision’s approach offers similar value in a digital format: create and compare reports without copy-pasting, filter by role and attribute, and track a player’s development arc across multiple sightings.
What this means practically for your own database is that every report entry should include the date and time of observation, the competition and venue, the match score and context (a player’s performance in a low-stakes 5-0 home win reads differently than the same player in a high-pressure derby), the specific minutes watched, and ratings across your chosen evaluation dimensions.
These contextual fields are what allow you to make honest comparisons across entries, because a player who looked excellent in one report might have been playing against a struggling opposition with ten men. The raw rating means very little without the context around it.
Video evidence, where you can get it, transforms the usefulness of every entry.
FIFA+ provides full-match replays and archive footage across hundreds of competitions at no cost, with a lean toward smaller leagues and tournaments, and many regional competitions now stream matches to YouTube. A short clip saved to a player’s profile, linked directly from YouTube or downloaded, does more for your ability to revisit and communicate your assessment than three paragraphs of written description.
The visual record and the written record together create something a decision-maker can actually act on.
CHECK OUT | How Funino Can Transform Youth Soccer Development
Building the Habit of Maintenance
A scouting database degrades the moment you stop updating it. This is not a technology problem, it is a discipline problem, and it is the reason most first attempts at building personal databases ultimately fail.
Players move clubs.
Contracts expire.
A midfielder you rated highly six months ago might have had a serious injury since your last report, or moved two divisions up, or lost form entirely. A database that does not reflect those changes misrepresents reality, and a database that misrepresents reality is worse than no database at all because it creates false confidence.
The practical solution is a weekly review habit rather than relying on ad hoc updates. Every week, you run through the players you have watched that week and enter their reports immediately, while the observations are fresh. Every fortnight or month, you run through your active watchlist and check for updates: new clubs, new contracts, notable performances.
This rhythm, consistently held, keeps the data alive without consuming disproportionate time. Platforms like ScoutingStats make this easier with a watchlist calendar feature that shows upcoming fixtures for every tracked player and prompts match-by-match assessments right after the final whistle.
The broader failure mode, which Scout52 flags directly in its own documentation, is over-complication. Building an elaborate system of linked sheets, colour-coded tier ratings, and nested categories that you then struggle to maintain consistently produces worse data than a simpler system you actually use every time.
The goal is institutional memory, the kind that means when someone asks you six months from now about a left back you watched twice last autumn, you can pull up two structured reports, a development note, and a current club status in under a minute.
CHECK OUT | Choosing Your Soccer Position: 7 Proven Steps for Young Players
The Competitive Advantage
There is a quality that no platform can replicate and no data provider can sell, and it is the most valuable thing your database accumulates over time. It is your unique coverage of territories that everyone else ignores.
Professional tools cover professional football. The enterprise platforms, the Wyscout licenses and the Opta feeds, exist entirely in the geography of footage and data that clubs already know how to navigate. The grassroots world, where the vast majority of professional footballers are first identified, has almost no structured intelligence infrastructure at all.
Your consistent, well-maintained database of players in your region, your competition focus, your specific geography, is not a substitute for professional tools. It is something the professional tools cannot produce. The player your database identified two years ago, before he had a senior contract, before he moved to a club with any visibility, might be the most valuable entry you ever made.
That is the logic behind building the system properly from the beginning, because you genuinely cannot predict which observation will eventually matter most.
The data map in 2026, post-FBref, pushes individual scouts and small clubs toward exactly this kind of differentiated coverage. As one analyst noted in the wake of January’s changes, picking a league outside the top five that nobody else is covering and going deeper on it than anyone else bothers to is “the fact the data is slightly harder to get is the point, because it’s what makes your work stand out.”
The same principle holds for scouting at the amateur level. The difficulty of operating where the tools do not reach is inseparable from the value of doing it well.
Build the database. Keep it updated. Trust what you actually see.

